Software Architecture Concepts: [ Part 7] Consistent Hashing
![Software Architecture Concepts: [ Part 7] Consistent Hashing](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1638222366108%2FqvGS6b1_H.png&w=3840&q=75)
One of the problems that we come up against when designing scalable & highly available systems is how can we partition and replicate data in our systems. Data partitioning is the process of distributing data across a set of nodes while Data Replication is making multiple copies of the same data and storing them on multiple servers for fault tolerance & improving performance & availability of the system.
Challenge with Data Partitioning
There are two challenges when we try to distribute data:
- How do we know on where to read or write data from ?
- If we decide to add / remove server nodes, how do we know what data will be moved from existing nodes to the new nodes? ie, how can we minimize amount of data that needs to be moved when a node leaves / joins our system?
The very simple approach to select node that we need to read from / write data to involves using a suitable hashing function to map data key to an integer, then to know which node in the system we need to store the data we apply modulo on this number and the total number of servers.
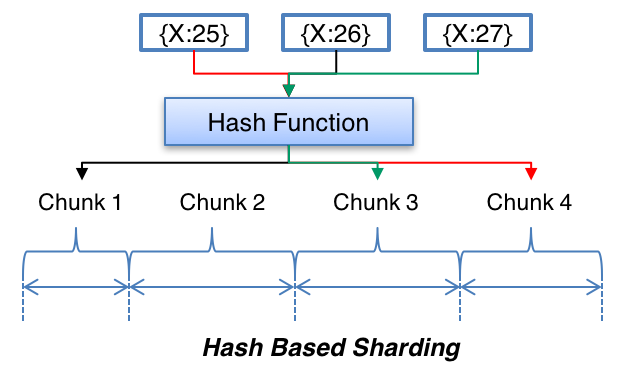
The scheme described in the above diagram solves the problem of finding a server for reading/writing the data. But when we add or remove a node, all our existing mappings will be broken. This is because the total number of nodes will be changed, which was used to find the actual server storing the data. In order to get things working again, we have to remap all the keys and move our data based on the new server count, which will be a complete mess!
Consistent Hashing
David Karger et al. first introduced Consistent Hashing in their 1997 paper. They suggested its use in distributed caching. Later, Consistent Hashing was adopted and enhanced to be used across many distributed systems.
Consistent Hashing maps data to physical nodes and ensures that only a small set of keys move when servers are added or removed.
Consistent Hashing uses a ring to represent how data and hardware nodes are stored in a system. both Nodes & Keys are hashed and plotted on the ring.
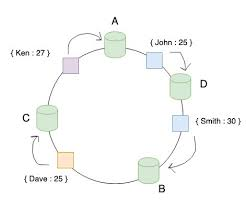
The Consistent Hashing scheme described above works great when a node is added or removed from the ring, as in these cases, since only the next node is affected. For example, when a node is removed, the next node becomes responsible for all of the keys stored on the outgoing node.
Virtual nodes
Inserting and removing nodes in any distributed system is very common. Current nodes can die due to software or hardware issues and may need to be replaces. Similarly, new nodes may be added to an existing cluster to meet growing demands. To handle these scenarios, Consistent Hashing introduces the concept of virtual nodes (Vnodes).
The basic Consistent Hashing algorithm assigns a single token to each node node. This has two problems
Hotspots: Each node is assigned one large range, if the data is not evenly distributed, some nodes can become hotspots.
Node rebuilding: Each node’s data can be replicated on a fixed number of other nodes, when we need to rebuild a node, only its replica nodes can provide the data. This puts a lot of pressure on the replica nodes and can lead to service degradation.
To handle these challenges, Instead of assigning a single token to a node, the hash range is divided into multiple smaller ranges, and each physical node is assigned several of these smaller ranges. Each of these subranges is considered a Vnode. With Vnodes, instead of a node being responsible for just one token, it is responsible for many tokens (or subranges).
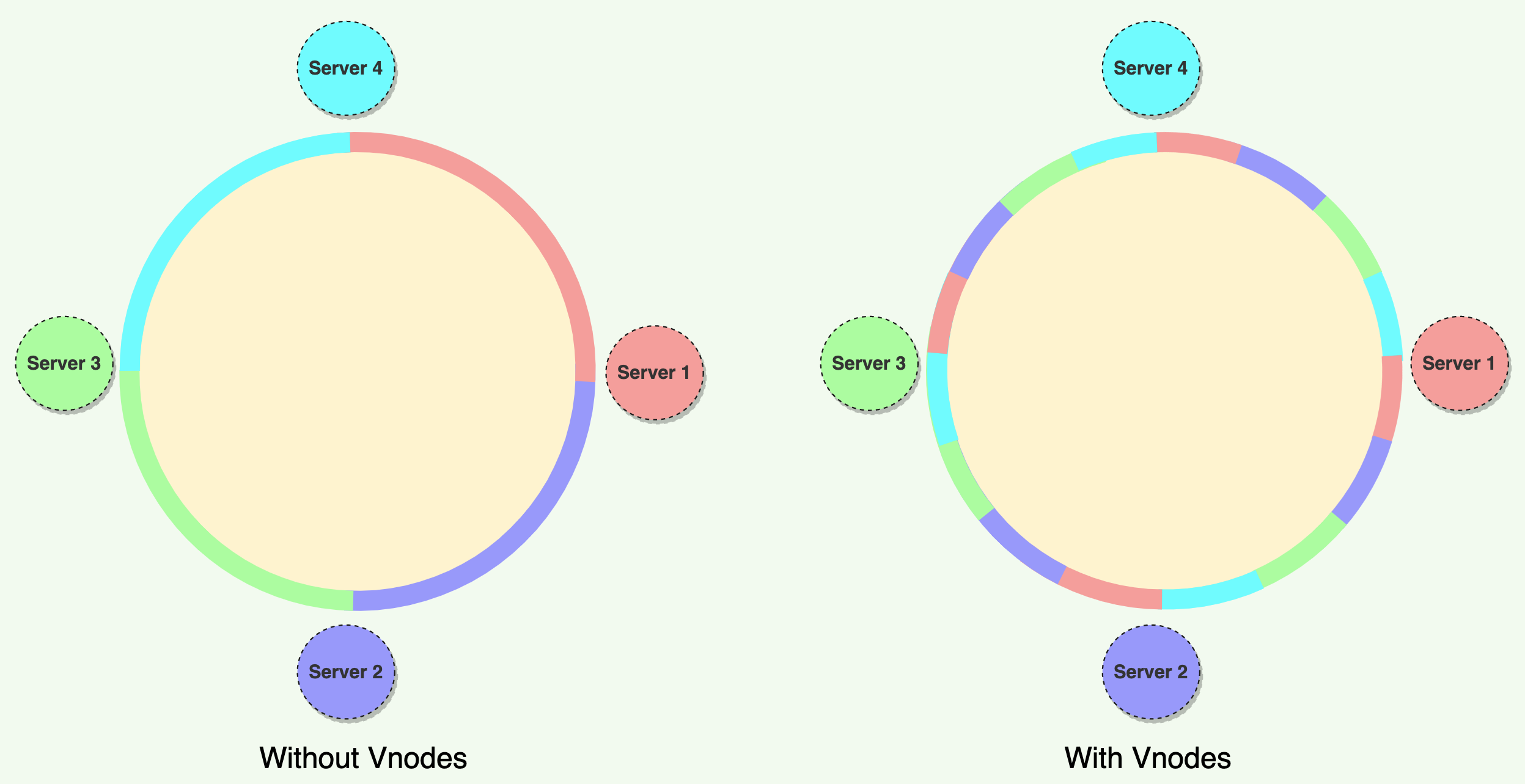
Vnodes are distributed randomly across the system and are generally non-contiguous so that no two adjacent Vnodes are assigned to the same physical node. Additionally, nodes do carry replicas of other nodes for fault tolerance.
Advantages of Vnodes
- Spread the load more evenly across the physical nodes
- Vnodes make it easier to maintain a system containing non identical machines (machines with more power can take more Vnodes)
- Vnodes help assign smaller ranges to each physical node, this decreases the probability of hotspots.
To ensure highly available and durability, each data item is replicated on multiple N nodes in the system where the value N is equivalent to the replication factor.
The replication factor is the number of nodes that will have the copy of the same data. For example, a replication factor of Three means there are Three copies of each data item, where each copy is stored on a different node.
Each key is will have a coordinator node (generally the first node that falls in the hash range), which first writes the data locally and then replicates it to N-1 clockwise successor nodes on the ring. In an eventually consistent system, this replication is done asynchronously (in the background).
Examples of Systems Using Consistent Hashing
Amazon’s Dynamo and Apache Cassandra use Consistent Hashing to distribute and replicate data across nodes.

![Information Security Series: [Part2] Principles of Privileges](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1647290198557%2FdaFz7fDND.png&w=3840&q=75)
![Information Security Series: [Part1] Principles of Security](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1647209120646%2FxVK4QYmwq.png&w=3840&q=75)