Software Architecture Concepts: [ Part 6] CAP Theorem & PACELC Theorem
![Software Architecture Concepts: [ Part 6] CAP Theorem & PACELC Theorem](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1637606952997%2FE9zSj7lIb.png&w=3840&q=75)
In distributed systems, failures will occur, e.g., servers can crash, disks can go bad resulting in data losses, or network connection can be lost, making a part of the system inaccessible. How can a distributed system model itself to get the maximum benefits out of different resources available?
CAP Theorem
CAP theorem states that it is impossible for a distributed system to simultaneously provide all three of the following desirable properties:
Consistency ( C ): All nodes in the system see the same data at the same time. This means users can read or write from/to any node in the system and will receive the same data. It is equivalent to having a single up-to-date copy of the data.
Availability ( A ): Availability means every request received by a working node in the system must result in a response. Even when network / hardware failures occur, every request must return a result. In other terms, availability refers to a system’s ability to remain accessible even if one or more nodes in the system go down.
Partition tolerance ( P ): A partition is a communication break (or a network failure) between any two nodes in the system, i.e., both nodes are up but cannot communicate with each other. A partition-tolerant system continues to operate even if there are partitions in the system. Such a system can sustain any network failure that does not result in the failure of the entire network. Data is sufficiently replicated across combinations of nodes and networks to keep the system up through intermittent outages.
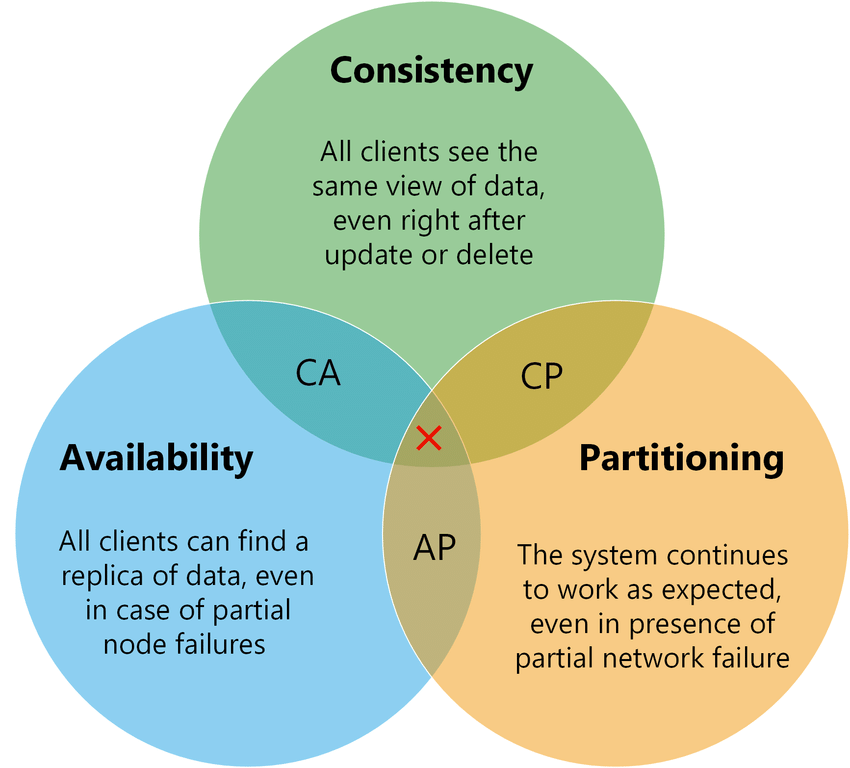
According to the CAP theorem, any distributed system needs to pick two out of the three properties. The three options are CA, CP, and AP. However, CA is not a reasonable option because a system that is not partition-tolerant will be forced to give up either Consistency or Availability in the case of a network partition.
Therefore, the theorem can really be stated as: In the presence of a network partition, a distributed system must choose either Consistency or Availability.
 .
.
PACELC Theorem
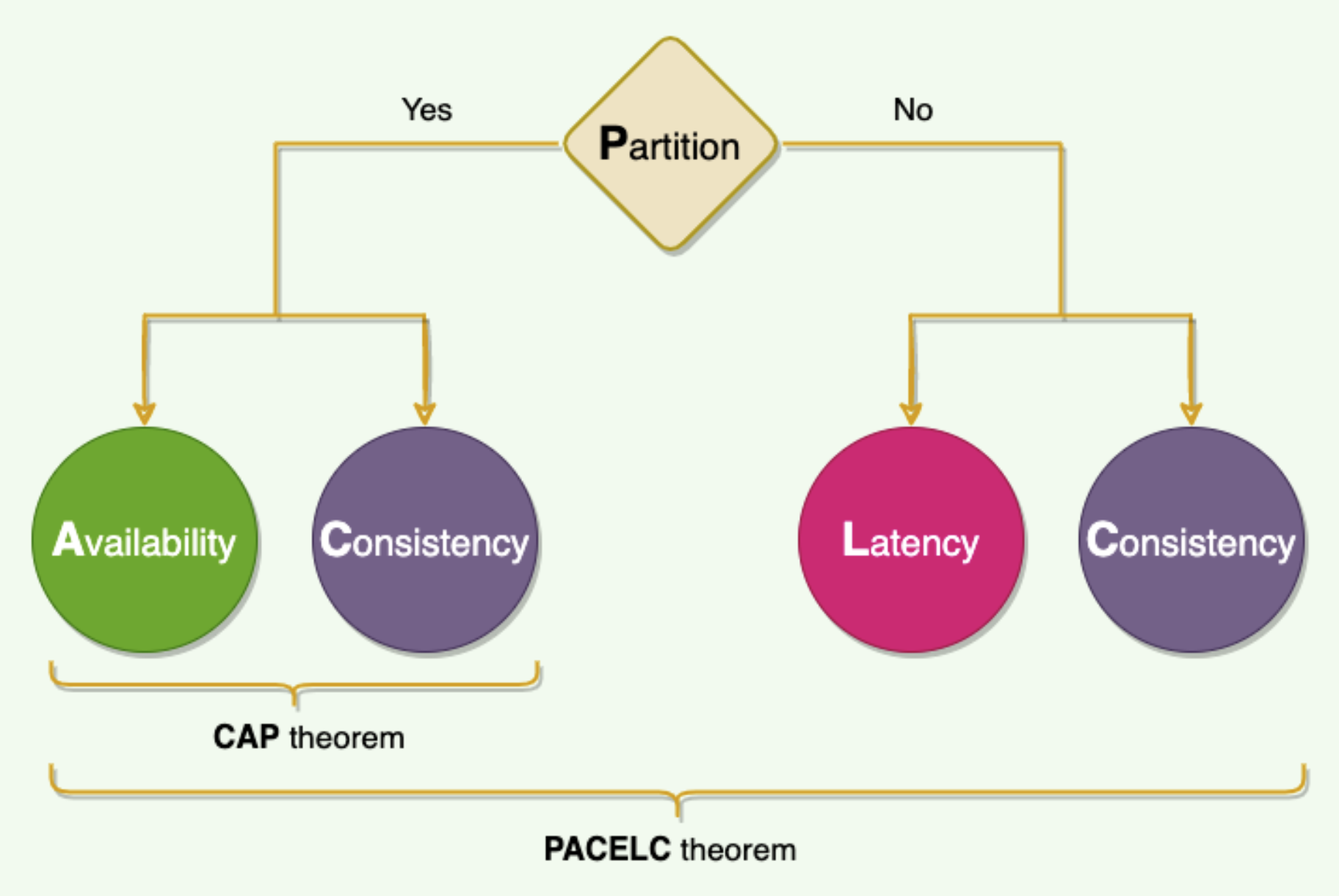
One place where the CAP theorem is silent is what happens when there is no network partition? What choices does a distributed system have when there is no partition?
The PACELC theorem states that in a system that replicates data:
if there is a partition ‘P’, a distributed system can choose between availability and consistency ('A' and 'C'); else ('E'), when the system is running normally without partitions, the system can tradeoff between latency ('L') and consistency ('C').
The first part of the theorem (PAC) is the same as the CAP theorem, and the ELC is the extension.
Example Systems
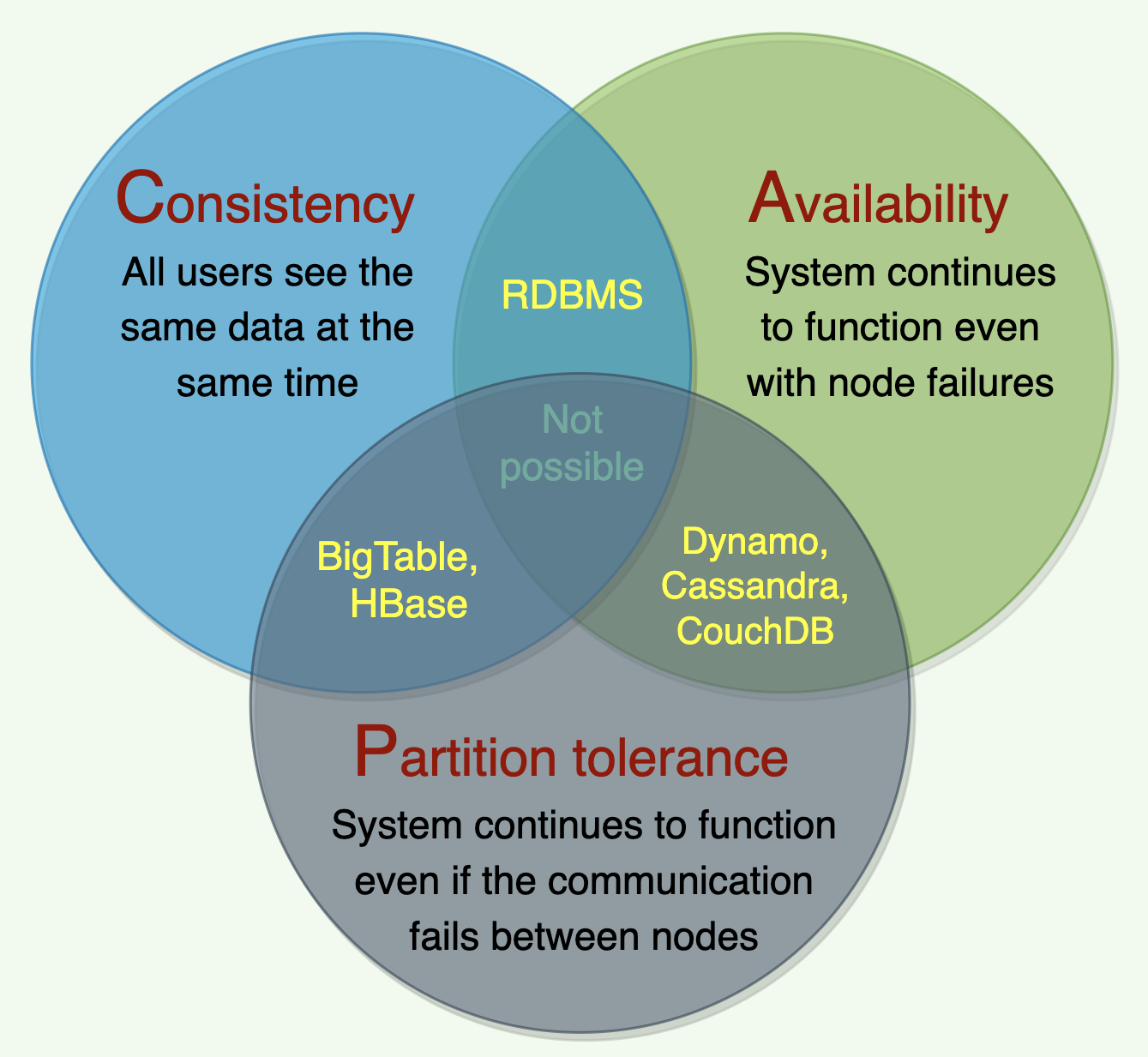
Dynamo and Cassandra are PA/EL systems: They choose availability over consistency when a partition occurs; otherwise, they choose better latency.
BigTable and HBase are PC/EC systems: They will always choose consistency, giving up availability and lower latency.
MongoDB can be considered PA/EC: MongoDB works in a primary/secondaries configuration. In the default configuration, all writes and reads are performed on the primary. As all replication is done asynchronously (from primary to secondaries), when there is a network partitions there is a loss of consistency during partitions.
When MongoDB is configured to write on majority replicas and read from the primary, it could be categorized as PC/EC.

![Information Security Series: [Part2] Principles of Privileges](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1647290198557%2FdaFz7fDND.png&w=3840&q=75)
![Information Security Series: [Part1] Principles of Security](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1647209120646%2FxVK4QYmwq.png&w=3840&q=75)